Why do you need Databricks Databricks-Certified-Professional-Data-Engineer Exam Dumps?
Wiki Article
For years our team has built a top-ranking brand with mighty and main which bears a high reputation both at home and abroad. The sales volume of the Databricks-Certified-Professional-Data-Engineer Study Materials we sell has far exceeded the same industry and favorable rate about our products is approximate to 100%. Why the clients speak highly of our Databricks-Certified-Professional-Data-Engineer study materials? Our dedicated service, high quality and passing rate and diversified functions contribute greatly to the high prestige of our products. We provide free trial service before the purchase, the consultation service online after the sale, free update service and the refund service in case the clients fail in the test.
The ITPassLeader wants to win the trust of Databricks Certified Professional Data Engineer Exam (Databricks-Certified-Professional-Data-Engineer) certification exam candidates. To achieve this objective ITPassLeader is presenting Valid, Real, and Updated Databricks Certified Professional Data Engineer Exam (Databricks-Certified-Professional-Data-Engineer) exam questions in three different formats. These formats have high demand in the market and offer the easiest and quick way for Databricks Certified Professional Data Engineer Exam (Databricks-Certified-Professional-Data-Engineer) exam preparation.
>> Reliable Exam Databricks-Certified-Professional-Data-Engineer Pass4sure <<
New Databricks-Certified-Professional-Data-Engineer Test Duration & Databricks-Certified-Professional-Data-Engineer Free copyright
In this way, the Databricks Databricks-Certified-Professional-Data-Engineer certified professionals can not only validate their skills and knowledge level but also put their careers on the right track. By doing this you can achieve your career objectives. To avail of all these benefits you need to pass the Databricks-Certified-Professional-Data-Engineer Exam which is a difficult exam that demands firm commitment and complete Databricks-Certified-Professional-Data-Engineer exam questions preparation.
Databricks Certified Professional Data Engineer Exam covers a wide range of topics related to data engineering using Databricks, including data ingestion, data transformation, data storage, and data orchestration. Databricks-Certified-Professional-Data-Engineer Exam also tests the candidate's proficiency in using Databricks tools and technologies such as Delta Lake, Apache Spark, and Databricks Runtime. Successful completion of the exam demonstrates that the candidate has the skills and knowledge required to design, build, and manage efficient and scalable data pipelines using Databricks. Databricks Certified Professional Data Engineer Exam certification also enhances the candidate's credibility and marketability in the job market, as it is recognized by leading organizations in the industry.
Databricks Certified Professional Data Engineer Exam Sample Questions (Q48-Q53):
NEW QUESTION # 48
A task orchestrator has been configured to run two hourly tasks. First, an outside system writes Parquet data to a directory mounted at /mnt/raw_orders/. After this data is written, a Databricks job containing the following code is executed:
(spark.readStream
.format( " parquet " )
.load( " /mnt/raw_orders/ " )
.withWatermark( " time " , " 2 hours " )
.dropDuplicates([ " customer_id " , " order_id " ])
.writeStream
.trigger(once=True)
.table( " orders " )
)
Assume that the fields customer_id and order_id serve as a composite key to uniquely identify each order, and that the time field indicates when the record was queued in the source system. If the upstream system is known to occasionally enqueue duplicate entries for a single order hours apart, which statement is correct?
- A. The orders table will not contain duplicates, but records arriving more than 2 hours late will be ignored and missing from the table.
- B. All records will be held in the state store for 2 hours before being deduplicated and committed to the orders table.
- C. The orders table will contain only the most recent 2 hours of records and no duplicates will be present.
- D. Duplicate records enqueued more than 2 hours apart may be retained and the orders table may contain duplicate records with the same customer_id and order_id.
Answer: A
Explanation:
* Exact extract: "dropDuplicates with watermark performs stateful deduplication on the keys within the watermark delay."
* Exact extract: "Records older than the event-time watermark are considered late and may be dropped." References: Structured Streaming watermarking and deduplication; One-time trigger.
NEW QUESTION # 49
A Delta Lake table was created with the below query:
Consider the following query:
DROP TABLE prod.sales_by_store -
If this statement is executed by a workspace admin, which result will occur?
- A. Data will be marked as deleted but still recoverable with Time Travel.
- B. An error will occur because Delta Lake prevents the deletion of production data.
- C. The table will be removed from the catalog but the data will remain in storage.
- D. Nothing will occur until a COMMIT command is executed.
- E. The table will be removed from the catalog and the data will be deleted.
Answer: E
Explanation:
When a table is dropped in Delta Lake, the table is removed from the catalog and the data is deleted. This is because Delta Lake is a transactional storage layer that provides ACID guarantees. When a table is dropped, the transaction log is updated to reflect the deletion of the table and the data is deleted from the underlying storage. References:
* https://docs.databricks.com/delta/quick-start.html#drop-a-table
* https://docs.databricks.com/delta/delta-batch.html#drop-table
NEW QUESTION # 50
A junior data engineer has been asked to develop a streaming data pipeline with a grouped aggregation using DataFrame df. The pipeline needs to calculate the average humidity and average temperature for each non- overlapping five-minute interval. Incremental state information should be maintained for 10 minutes for late- arriving data.
Streaming DataFrame df has the following schema:
"device_id INT, event_time TIMESTAMP, temp FLOAT, humidity FLOAT"
Code block:
Choose the response that correctly fills in the blank within the code block to complete this task.
- A. withWatermark("event_time", "10 minutes")
- B. await("event_time + '10 minutes'")
- C. awaitArrival("event_time", "10 minutes")
- D. slidingWindow("event_time", "10 minutes")
- E. delayWrite("event_time", "10 minutes")
Answer: A
Explanation:
The correct answer is A. withWatermark("event_time", "10 minutes"). This is because the question asks for incremental state information to be maintained for 10 minutes for late-arriving data. The withWatermark method is used to define the watermark for late data. The watermark is a timestamp column and a threshold that tells the system how long to wait for late data. In this case, the watermark is set to 10 minutes. The other options are incorrect because they are not valid methods or syntax for watermarking in Structured Streaming. References:
* Watermarking: https://docs.databricks.com/spark/latest/structured-streaming/watermarks.html
* Windowed aggregations: https://docs.databricks.com/spark/latest/structured-streaming/window- operations.html
NEW QUESTION # 51
You are currently asked to work on building a data pipeline, you have noticed that you are currently working on a very large scale ETL many data dependencies, which of the following tools can be used to address this problem?
- A. AUTO LOADER
- B. SQL Endpoints
- C. DELTA LIVE TABLES
- D. STRUCTURED STREAMING with MULTI HOP
- E. JOBS and TASKS
Answer: C
Explanation:
Explanation
The answer is, DELTA LIVE TABLES
DLT simplifies data dependencies by building DAG-based joins between live tables. Here is a view of how the dag looks with data dependencies without additional meta data,
1.create or replace live view customers
2.select * from customers;
3.
4.create or replace live view sales_orders_raw
5.select * from sales_orders;
6.
7.create or replace live view sales_orders_cleaned
8.as
9.select sales.* from
10.live.sales_orders_raw s
11. join live.customers c
12.on c.customer_id = s.customer_id
13.where c.city = 'LA';
14.
15.create or replace live table sales_orders_in_la
16.selects from sales_orders_cleaned;
Above code creates below dag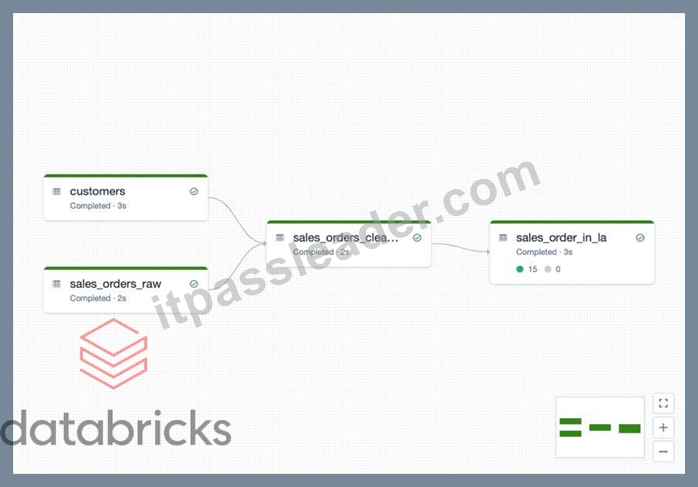
Documentation on DELTA LIVE TABLES,
https://databricks.com/product/delta-live-tables
https://databricks.com/blog/2022/04/05/announcing-generally-availability-of-databricks-delta-live-tables-dlt.htm DELTA LIVE TABLES, addresses below challenges when building ETL processes
1.Complexities of large scale ETL
a.Hard to build and maintain dependencies
b.Difficult to switch between batch and stream
2.Data quality and governance
a.Difficult to monitor and enforce data quality
b.Impossible to trace data lineage
3.Difficult pipeline operations
a.Poor observability at granular data level
b.Error handling and recovery is laborious
NEW QUESTION # 52
A data engineer is performing a join operating to combine values from a static userlookup table with a streaming DataFrame streamingDF.
Which code block attempts to perform an invalid stream-static join?
- A. userLookup.join(streamingDF, ["userid"], how="inner")
- B. streamingDF.join(userLookup, ["user_id"], how="left")
- C. streamingDF.join(userLookup, ["userid"], how="inner")
- D. userLookup.join(streamingDF, ["user_id"], how="right")
- E. streamingDF.join(userLookup, ["user_id"], how="outer")
Answer: D
Explanation:
In Spark Structured Streaming, certain types of joins between a static DataFrame and a streaming DataFrame are not supported. Specifically, a right outer join where the static DataFrame is on the left side and the streaming DataFrame is on the right side is not valid. This is because Spark Structured Streaming cannot handle scenarios where it has to wait for new rows to arrive in the streaming DataFrame to match rows in the static DataFrame. The other join types listed (inner, left, and full outer joins) are supported in streaming-static DataFrame joins.
:
Structured Streaming Programming Guide: Join Operations
Databricks Documentation on Stream-Static Joins: Databricks Stream-Static Joins
NEW QUESTION # 53
......
If you always feel that you can't get a good performance when you come to the exam room. There is Software version of our Databricks-Certified-Professional-Data-Engineer exam copyright, it can simulate the real exam environment. If you take good advantage of this Databricks-Certified-Professional-Data-Engineer practice materials character, you will not feel nervous when you deal with the Real Databricks-Certified-Professional-Data-Engineer Exam. Furthermore, it can be downloaded to all electronic devices so that you can have a rather modern study experience conveniently. Why not have a try?
New Databricks-Certified-Professional-Data-Engineer Test Duration: https://www.itpassleader.com/Databricks/Databricks-Certified-Professional-Data-Engineer-dumps-pass-exam.html
- Actual Databricks Databricks-Certified-Professional-Data-Engineer Practice Test - Quick Test Preparation Tips ???? Open ▶ www.validtorrent.com ◀ and search for [ Databricks-Certified-Professional-Data-Engineer ] to download exam materials for free ????Databricks-Certified-Professional-Data-Engineer Pass4sure Study Materials
- Reliable Databricks-Certified-Professional-Data-Engineer Exam Online ???? Reliable Databricks-Certified-Professional-Data-Engineer Exam Online ???? Valid Exam Databricks-Certified-Professional-Data-Engineer copyright ⬛ Search on ▛ www.pdfvce.com ▟ for ✔ Databricks-Certified-Professional-Data-Engineer ️✔️ to obtain exam materials for free download ????Databricks-Certified-Professional-Data-Engineer Reliable Test Tips
- Free PDF Databricks-Certified-Professional-Data-Engineer - High Hit-Rate Reliable Exam Databricks Certified Professional Data Engineer Exam Pass4sure ???? Easily obtain free download of { Databricks-Certified-Professional-Data-Engineer } by searching on “ www.examcollectionpass.com ” ????Accurate Databricks-Certified-Professional-Data-Engineer Answers
- Quiz High-quality Databricks - Databricks-Certified-Professional-Data-Engineer - Reliable Exam Databricks Certified Professional Data Engineer Exam Pass4sure ???? Search for 《 Databricks-Certified-Professional-Data-Engineer 》 and download it for free on 「 www.pdfvce.com 」 website ????Valid Test Databricks-Certified-Professional-Data-Engineer Format
- Quiz High-quality Databricks - Databricks-Certified-Professional-Data-Engineer - Reliable Exam Databricks Certified Professional Data Engineer Exam Pass4sure ???? Search on ▷ www.prep4sures.top ◁ for ⮆ Databricks-Certified-Professional-Data-Engineer ⮄ to obtain exam materials for free download ????Regualer Databricks-Certified-Professional-Data-Engineer Update
- Databricks-Certified-Professional-Data-Engineer New copyright ???? Databricks-Certified-Professional-Data-Engineer Latest Exam Forum ???? Databricks-Certified-Professional-Data-Engineer Reliable Exam Simulations ???? Immediately open “ www.pdfvce.com ” and search for ➠ Databricks-Certified-Professional-Data-Engineer ???? to obtain a free download ????Reliable Databricks-Certified-Professional-Data-Engineer Exam Papers
- How Can www.prepawaypdf.com Databricks-Certified-Professional-Data-Engineer Practice Questions be Helpful in Exam Preparation? ???? Easily obtain free download of “ Databricks-Certified-Professional-Data-Engineer ” by searching on ▛ www.prepawaypdf.com ▟ ⏸Regualer Databricks-Certified-Professional-Data-Engineer Update
- Fast Download Reliable Exam Databricks-Certified-Professional-Data-Engineer Pass4sure - Authoritative New Databricks-Certified-Professional-Data-Engineer Test Duration - Accurate Databricks Databricks Certified Professional Data Engineer Exam ???? Easily obtain free download of ▶ Databricks-Certified-Professional-Data-Engineer ◀ by searching on ➡ www.pdfvce.com ️⬅️ ????Accurate Databricks-Certified-Professional-Data-Engineer Answers
- Databricks-Certified-Professional-Data-Engineer Simulation Questions ???? Latest Databricks-Certified-Professional-Data-Engineer Exam Answers ???? Latest Databricks-Certified-Professional-Data-Engineer Exam Answers ???? Download ➠ Databricks-Certified-Professional-Data-Engineer ???? for free by simply entering ➤ www.troytecdumps.com ⮘ website ????Valid Test Databricks-Certified-Professional-Data-Engineer Format
- Reliable Exam Databricks-Certified-Professional-Data-Engineer Pass4sure | Valid Databricks-Certified-Professional-Data-Engineer: Databricks Certified Professional Data Engineer Exam 100% Pass ⚡ Search for ☀ Databricks-Certified-Professional-Data-Engineer ️☀️ and easily obtain a free download on ⮆ www.pdfvce.com ⮄ ????Reliable Databricks-Certified-Professional-Data-Engineer Exam Online
- How Can www.examcollectionpass.com Databricks-Certified-Professional-Data-Engineer Practice Questions be Helpful in Exam Preparation? ???? Search for ▛ Databricks-Certified-Professional-Data-Engineer ▟ and easily obtain a free download on ➤ www.examcollectionpass.com ⮘ ????Reliable Databricks-Certified-Professional-Data-Engineer Test Review
- janicebhbx091610.liberty-blog.com, myportal.utt.edu.tt, myportal.utt.edu.tt, myportal.utt.edu.tt, myportal.utt.edu.tt, myportal.utt.edu.tt, myportal.utt.edu.tt, myportal.utt.edu.tt, myportal.utt.edu.tt, myportal.utt.edu.tt, myportal.utt.edu.tt, bookmarkpagerank.com, rajaneudi916087.blogofchange.com, amiekurv871084.blogaritma.com, maciejvcz595554.celticwiki.com, mayavdvg569658.blog4youth.com, course.cost-ernst.eu, lorimhfy745293.blogsumer.com, freeurldirectory.com, Disposable vapes